Non tutti i modelli pubblicati sono dei benchmark validi
October 15, 2025Allenare un modello con tecniche di deep learning può essere una vera rottura se non sai come impostare correttamente gli iperparametri. Per evitare inutili mal di testa, puoi fare il tuning e trovare quel sottoinsieme di valori che ottimizzerà le performance del tuo modello. Oppure, se hai poco tempo, puoi fare una piccola ricerca e vedere se qualcuno ha già addestrato il modello. Puoi recuperare la configurazione degli iperparametri e usare i loro risultati come benchmark per il tuo modello. Il senso di fare ciò è avere un punto di partenza per il tuo tuning e un benchmark da migliorare, se possibile. Questo è praticamente quello che volevo fare in uno degli ultimi progetti che ho svolto in università.
Il mio compito
Il mio compito era allenare un modello in grado di rilevare rifiuti di plastica sulle superfici d’acqua come fiumi e laghi. Ho lavorato con un mio amico ed entrambi abbiamo deciso di usare l’architettura YOLOv8 e allenarla con un dataset che era disponibile per il nostro progetto.1 Abbiamo fatto alcuni esperimenti senza ottenere alcun risultato degno di nota in termini di performance, così ci siamo guardati in giro cercando articoli accademici o qualche post su internet che potesse risultare rilevante. Siamo incappati principalmente in paper sulla detection con dataset contenenti immagini satellitari… tranne uno studio pubblicato all’inizio del 20242 che era legato esattamente al nostro stesso dataset e modello. Che fortuna. Così, leggendo il paper, abbiamo scoperto che potevamo raggiungere buone performance con una configurazione specifica. Fantastico!
Proviamo a replicare quei risultati e… nope, ancora risultati scadenti con una loss di validazione alta. Forse avevamo eseguito il training con qualche iperparametro o dettaglio diversi. Proviamo di nuovo, ma con gli esatti stessi valori di iperparametri. Ancora niente. Le performance non volevano migliorare.
WTF?!
Sembra ragionevole cercare bug o errori di configurazione da parte nostra (dopotutto, ero ancora uno studente magistrale), ma quando niente di ciò che provi è in grado di dare risultati migliori, inizi ad avere dei dubbi.
Siamo sicuri che le performance mostrate nel paper siano legittime? Non è che c’è qualche dettaglio che non torna?
Quindi dovevamo fare solo una cosa: trovare un metodo per replicare i loro risultati, anche a costo di fare supposizioni stupide sul dataset, sul modello o sulle tecniche utilizzate. E l’abbiamo fatto. Abbiamo continuato ad addestrare modelli usando configurazioni “sbagliate” finché non abbiamo scoperto che il problema dello studio accademico non era affatto negli iperparametri, ma in come avevano usato il dataset.
Domanda: cosa succede se alleni un modello con un train set (cioè, un dataset
usato per la fase di addestramento) e poi usi lo
stesso identico train set anche come val set (cioè, il dataset il cui scopo
è validare il modello)? Spoiler: ottieni risultati che sembrano fantastici, ma
con lo stesso modello di merda.
Entriamo nei dettagli
Il dataset usato 1 contiene 3 sottoinsiemi diversi, train, val e test,
ognuno progettato per il suo scopo specifico, come ho detto prima in quella
domanda sarcastica (il test set è usato per testare il modello una volta
completata la fase di addestramento).
Dentro ogni sottoinsieme, ci sono un sacco di immagini diverse etichettate con 4
diversi tipi di classi usando la specifica YOLO (dai un’occhiata alla documentazione di YOLO per saperne di più).
Per valutare la bontà del modello addestrato, si usano molte metriche, come
precision, recall e funzioni di loss.
In particolare, per i modelli di object detection, le principali funzioni di
loss sono la box_loss e la cls_loss. La cls_loss (loss di classificazione)
ci dice il tasso di errata classificazione, e la box_loss ci dice l’errore
durante il disegno del riquadro (box) sugli oggetti rilevati.
Ma una delle migliori metriche che riassume quanto è realmente buono il modello
di detection è la mAP50: mean average precision su tutte le classi usate.
Di nuovo, per maggiori dettagli sulle metriche che si possono usare nei modelli
di object detection, controlla la documentazione qui.
Per semplicità, mi concentrerò solo sulla mAP50: questa metrica percentuale
significa semplicemente “più alto è, meglio è”, dove 100% è la perfezione.
Con i nostri test effettivi (usando il val set corretto), siamo riusciti a
raggiungere solo un mAP50 complessivo del 39.1%. Non era un granché, visto che
il modello era performante con una classe specifica, PLASTIC_BOTTLE, e scarso
con le altre. E come potete vedere nei grafici seguenti, non c’è margine di
miglioramento perché il modello andrebbe solo in overfitting con ulteriore training.
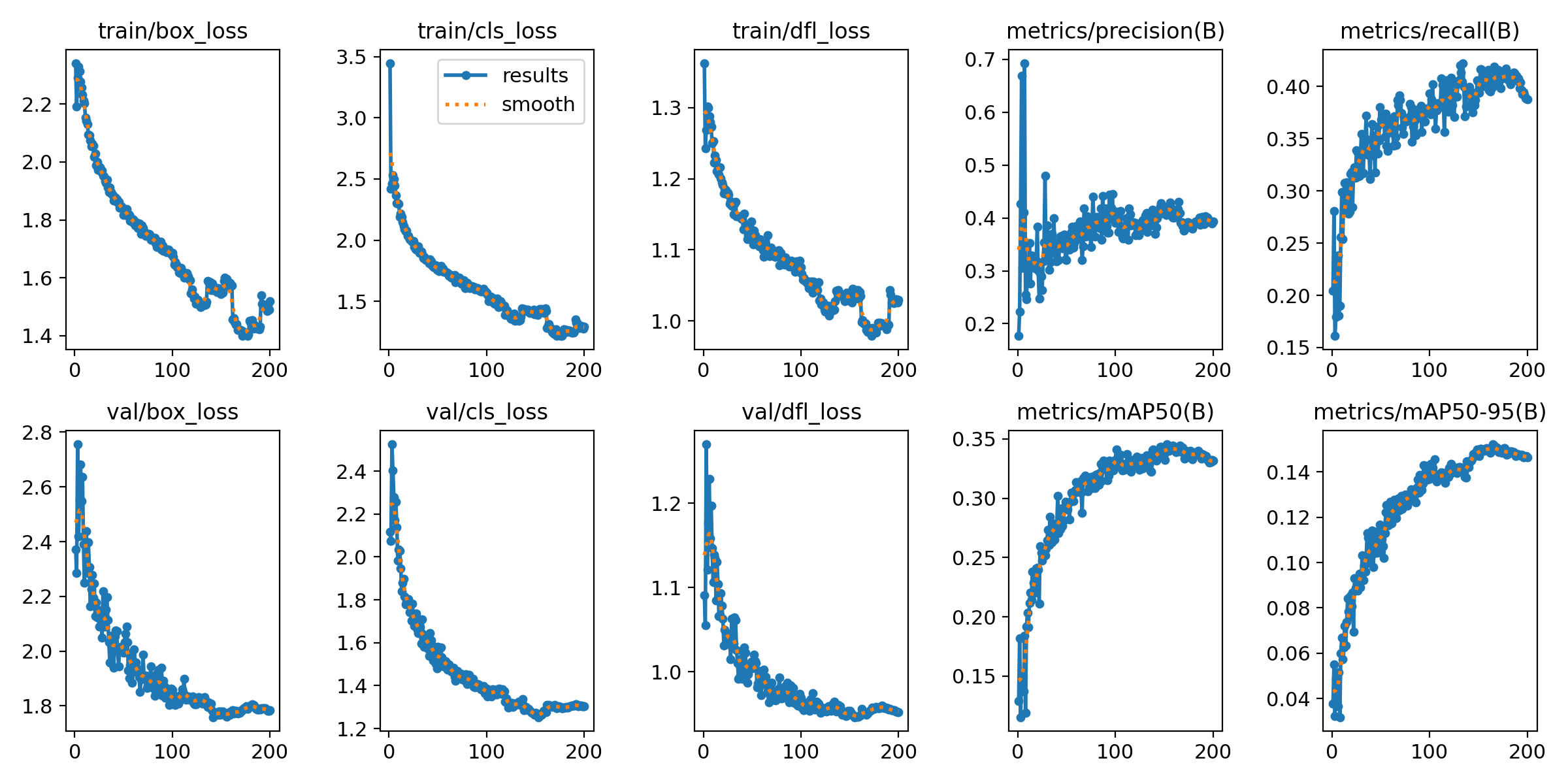 Funzioni di loss e metriche del nostro modello allenato (quello legittimo)
Funzioni di loss e metriche del nostro modello allenato (quello legittimo)
Come potete vedere, queste metriche non erano neanche lontanamente buone come quelle del paper. Gli autori sostenevano che il loro modello potesse raggiungere il 68.8%!
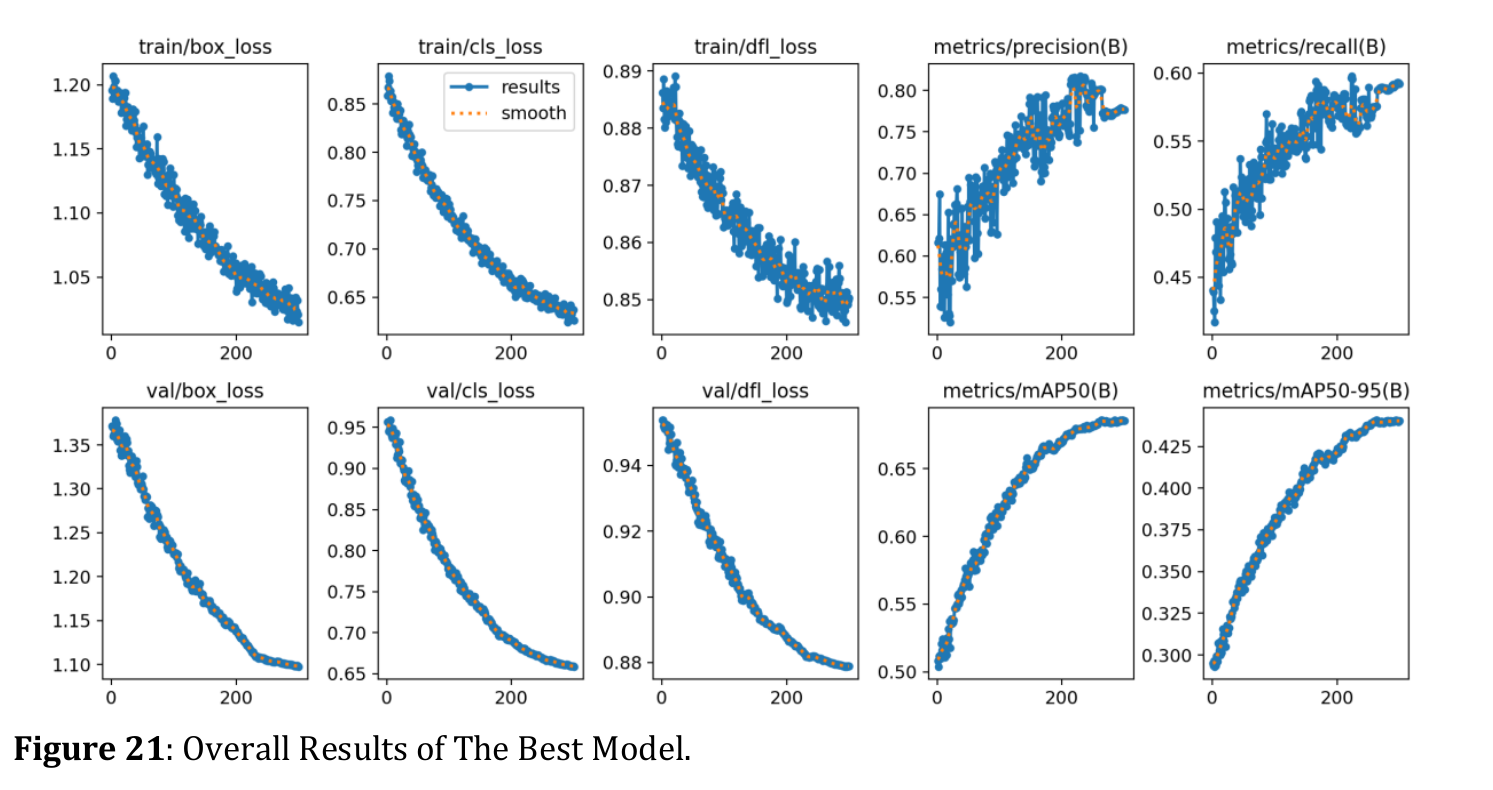 Funzioni di loss e metriche del modello del paper (scusate per la bassa risoluzione dell’immagine)
Funzioni di loss e metriche del modello del paper (scusate per la bassa risoluzione dell’immagine)
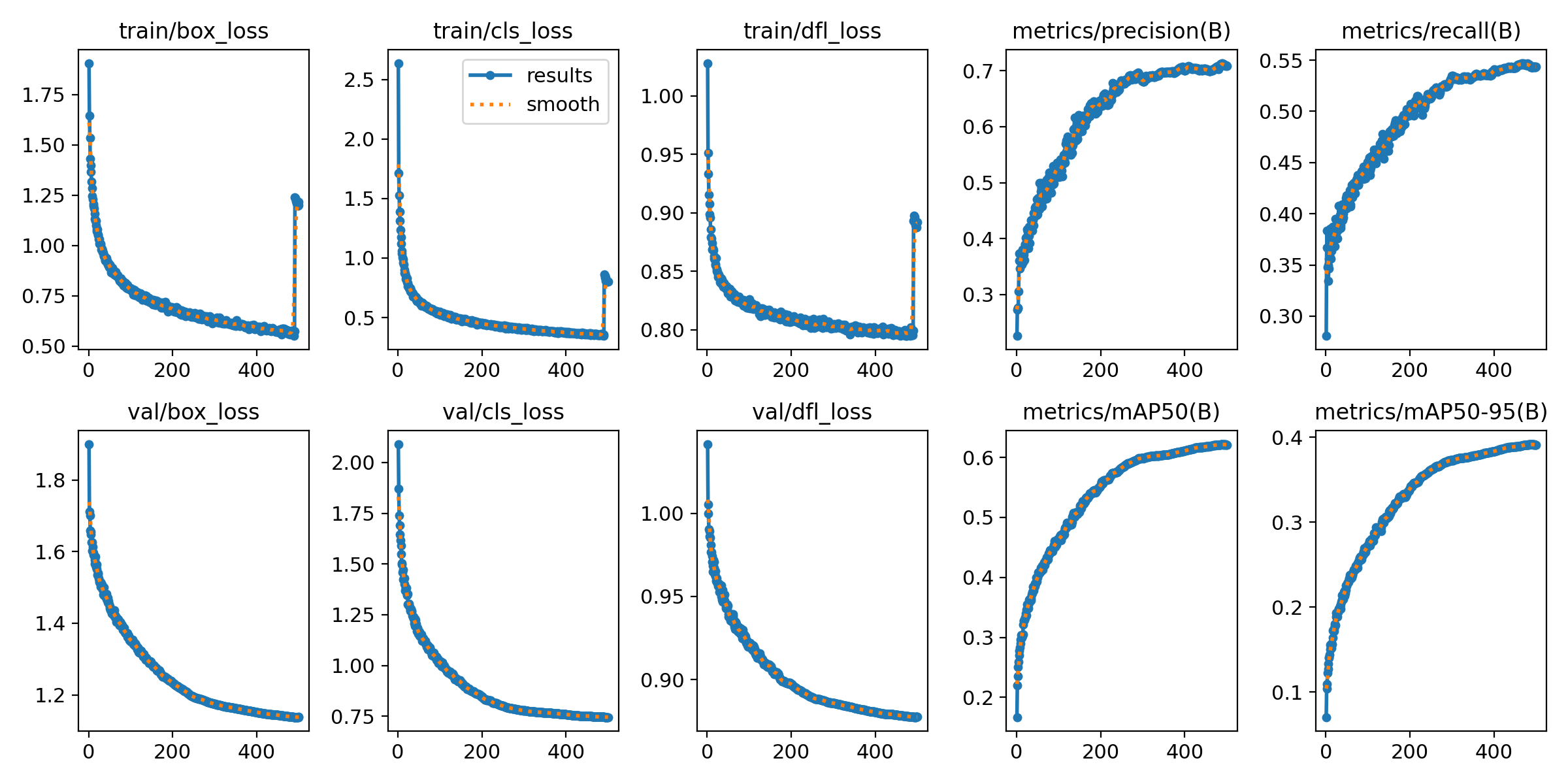 E guardate un po’! I nostri risultati quando copiamo il loro errore. Praticamente lo stesso comportamento.
E guardate un po’! I nostri risultati quando copiamo il loro errore. Praticamente lo stesso comportamento.
Ok, perché è così grave?
Quindi, perché questa cosa è così grave? Come potete vedere dai nostri risultati “falsati” (la terza immagine), le metriche sembrano fantastiche. La validation loss crolla e il mAP50 schizza al 62.1%, praticamente proprio come sosteneva il paper. Ma il modello non sta imparando nulla. Sta memorizzando.
Pensatela così: è come dare a uno studente un test di pratica da 100 domande e poi dargli come esame finale le stesse identiche 100 domande. Lo studente prenderebbe il massimo dei voti, giusto? Ma ha davvero imparato la materia? Neanche per idea. Ha solo imparato a memoria le risposte.
È esattamente quello che sta succedendo qui. Il val set dovrebbe essere il
“vero test” per controllare se il modello è in grado di generalizzare, cioè se
riesce a trovare la plastica in immagini nuove che non ha mai visto prima.
Usando il train set come val set, il modello impara semplicemente a memoria
i dati di training. Non sta imparando a rilevare le caratteristiche di una
bottiglia di plastica; sta imparando “nell’immagine_123.jpg, c’è un riquadro
alle coordinate [x, y, w, h]”. Questa è la definizione classica di overfitting,
ed è un errore colossale nel machine learning.
Il modello sembra un genio sulla carta, ma è completamente inutile nel mondo
reale. Nell’istante in cui gli daresti una foto nuova dal test set,
fallirebbe miseramente.
Quindi, la morale della favola? Siate sempre scettici. Solo perché qualcosa è
“pubblicato” non significa che sia valido e corretto. Cercate sempre di
replicare i risultati, e se qualcosa puzza (o è troppo bello per essere vero),
probabilmente lo è. Fidatevi del vostro val set… purché sia quello giusto!