Not every published model is a valid benchmark
October 15, 2025Training a model with deep learning techniques can be a total pain if you don’t know how to set up your hyperparameters properly. To avoid the headache, you can tune them and find the subset of values that will optimize the performance of your model. Or, if you’re short on time, you can do a little research and see if somebody already did the tuning part. You can snag their hyperparameters configuration and also take their results as a benchmark for your model. The whole point of doing that is to get a starting point for your tuning and a benchmark to improve, if possible. This is pretty much what I wanted to do in one of the last projects that I did at university.
My assignment
My assignment was to train a model that is able to detect plastic waste on water surfaces like rivers and lakes. I worked with a friend of mine, and we both decided to use the YOLOv8 architecture and train it with a dataset that was available for our project.1 We did some experiments without any great results in performance, so we looked around for academic papers or some posts on the internet that seemed relevant. We mostly bumped into papers about detection with datasets containing satellite images… except for one study published in early 20242 that was related to our exact same dataset and model. Lucky us. So, after reading the paper, we found out that we could reach good performance with a specific configuration. Nice!
Let’s try if we can replicate those results and… nope, still got garbage results with high evaluation loss. Maybe we ran the training with some different hyperparameter or other details. Let’s try again, but with the exact same values as hyperparameters. Still nothing. The performance just wouldn’t budge.
WTF?!
It seems reasonable to look for bugs or misconfigurations on our end (after all, I was only a master’s student), but when nothing you try is able to give better results, you start to have some doubts.
Are we sure that the performance shown in the paper is legit? Is there some kind of catch in it?
So, to answer that, we had to do only one thing: find a method to replicate their results, even if it meant making stupid assumptions about the dataset, model, or techniques. And we did it. We kept making “wrong” configurations until we found out that the problem with the academic study wasn’t in the hyperparameters at all, but with how they used the dataset.
Trivia: what happens if you train a model with a train set (as in, a dataset
used for the training phase) and then you use the very same train set also as
the val set (as in, the dataset whose whole purpose is to validate the model)?
Spoiler: you get amazing-looking results but the same shitty model.
Diving into details
The dataset used 1 contains 3 different subsets, train, val and test,
each designed for its specific purpose, as I mentioned in that sarcastic
question earlier (the test set is used to test the model once the training
phase is completed).
Inside each subset, there are a bunch of different images labeled with 4
different kinds of classes using the YOLO specification (see the YOLO documentation to learn more about it).
In order to evaluate how good the model is, many metrics are used like precision,
recall and loss functions.
In particular for object detection models, the main loss functions are the
box_loss and cls_loss. The cls_loss (classification loss) tells us the
misclassification rate, and the box_loss (box loss) tells us the error during
the drawing of the box over the detected objects.
But one of the best metrics that summarizes how good the detection model really
is is the mAP50: mean average precision over all classes used.
Again, for more details about the metrics that can be used in object detection
models check the documentation here.
For simplicity, I’ll just talk about the mAP50 here: this percentage metric
just means “higher is better”, with 100% being perfect.
With our actual tests (using the correct val set, )we were only able to reach
an overall mAP50 of 39.1%. This wasn’t very good, since the model was good
with a specific class, PLASTIC_BOTTLE and bad with the others. And as you can
see in the following graphs there is no margin of improvement because the model
would just overfit with extra training.
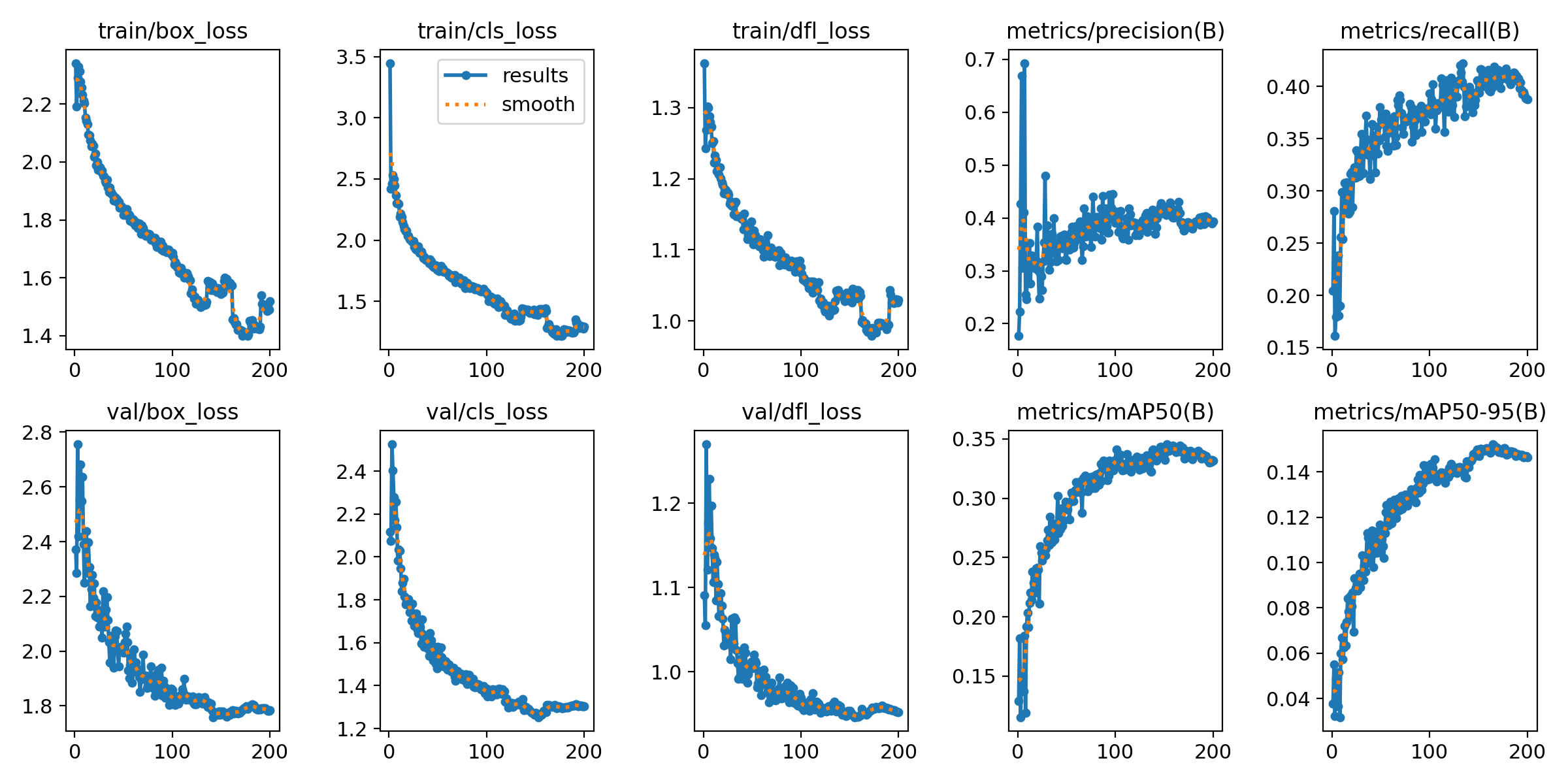 Loss functions and metrics of our (legit) trained model
Loss functions and metrics of our (legit) trained model
As you can see, these metrics weren’t nearly as good as those in the paper. The authors claimed their model could reach 68.8%!
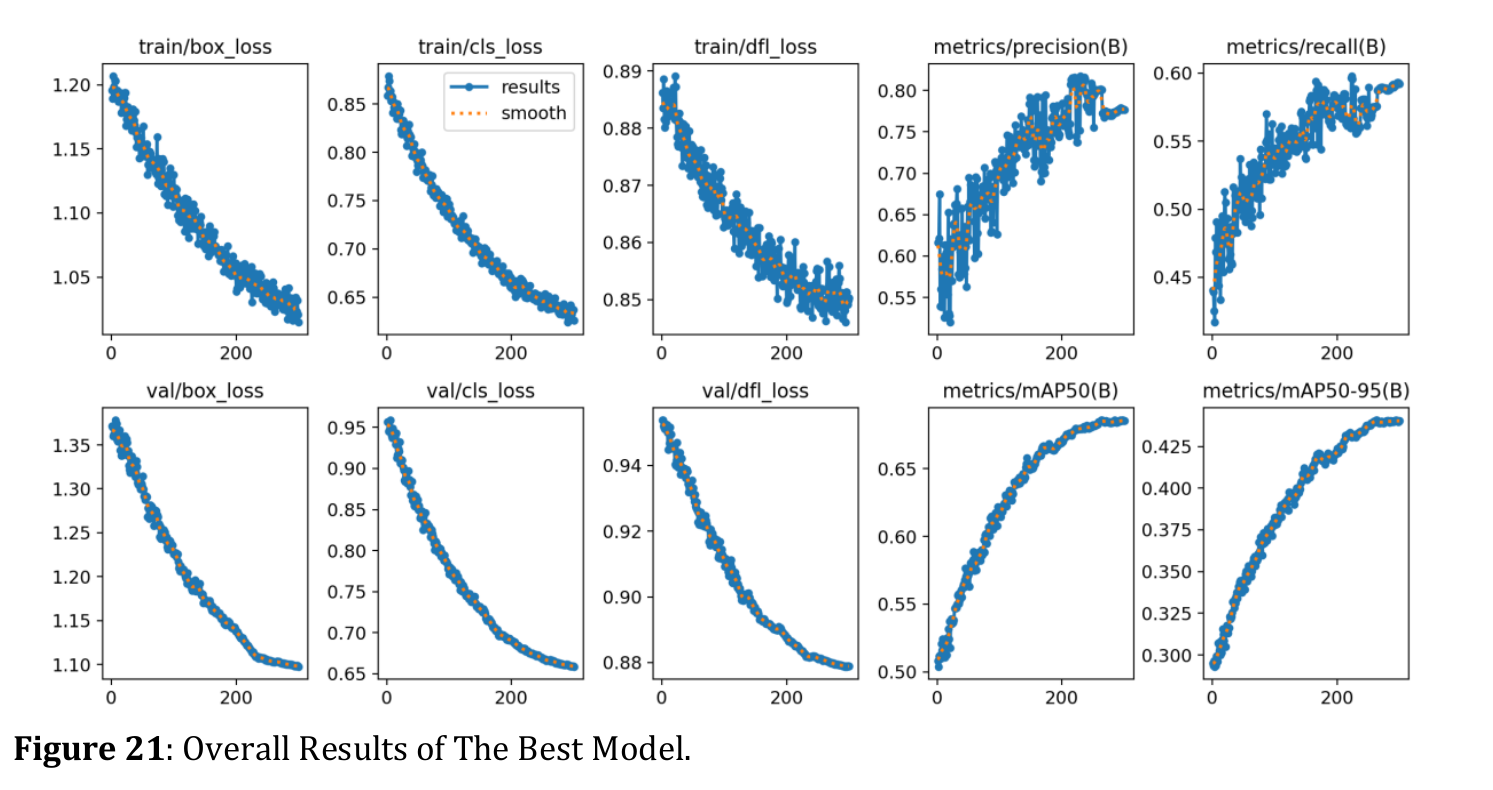 Loss functions and metrics from the paper (sorry for bad image resolution)
Loss functions and metrics from the paper (sorry for bad image resolution)
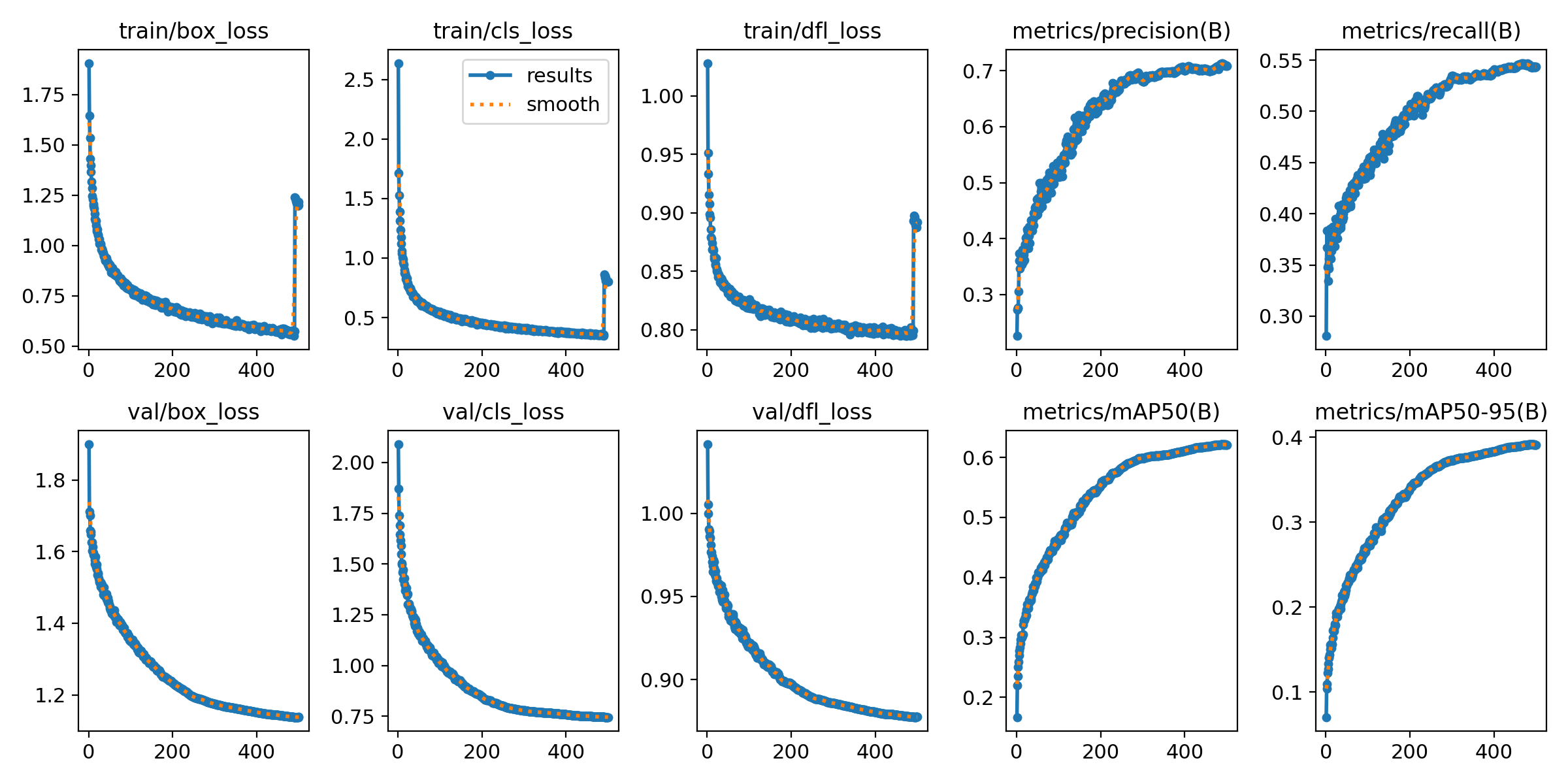 And look at that! Our results when we copy their mistake. Quite the same behavior
And look at that! Our results when we copy their mistake. Quite the same behavior
Ok, why is it bad?
So, why is this so bad?
As you can see from our “fake” results (that third image), the metrics look
amazing. The validation loss plummets, and the mAP50 shoots up to 62.1%, pretty
much just like the paper claimed.
But the model isn’t learning anything. It’s memorizing.
Think of it this way: It’s like giving a student a 100-question practice test and then making their final exam the exact same 100 questions. The student would get a perfect score, right? But did they actually learn the subject? Hell no. They just memorized the answers.
That’s exactly what’s happening here. The val set is supposed to be the “real
test” to check if the model can generalize—if it can find plastic in new images
it’s never seen before.
By using the train set as the val set, the model just memorizes the training
data. It’s not learning to detect the features of a plastic bottle; it’s
learning “in image_123.jpg, there is a box at [x, y, w, h].” This is the classic
definition of overfitting, and it’s a massive ML mistake.
The model looks like a genius on paper, but it’s completely useless in the real world. The second you’d give it an actual new photo from the test set, it would fail hard.
So the big takeaway? Always be skeptical. Just because something is “published”
doesn’t mean it’s correct. Always try to replicate the results, and if something
looks fishy (or way too good to be true), it probably is. Trust your val set…
as long as it’s the right one!